
🚨 Скорее всего, вы ещё не слышали об ИИ от Microsoft, который способен распознавать 60-минутную аудиозапись за один проход.
Потому что большинство подобных инструментов работают так:
Разбивают аудио на маленькие части → обрабатывают каждый фрагмент отдельно → затем снова собирают результат.
На каждом разрезе теряется контекст. Система забывает, кто говорит. Тема разговора распадается.
VibeVoice работает иначе.


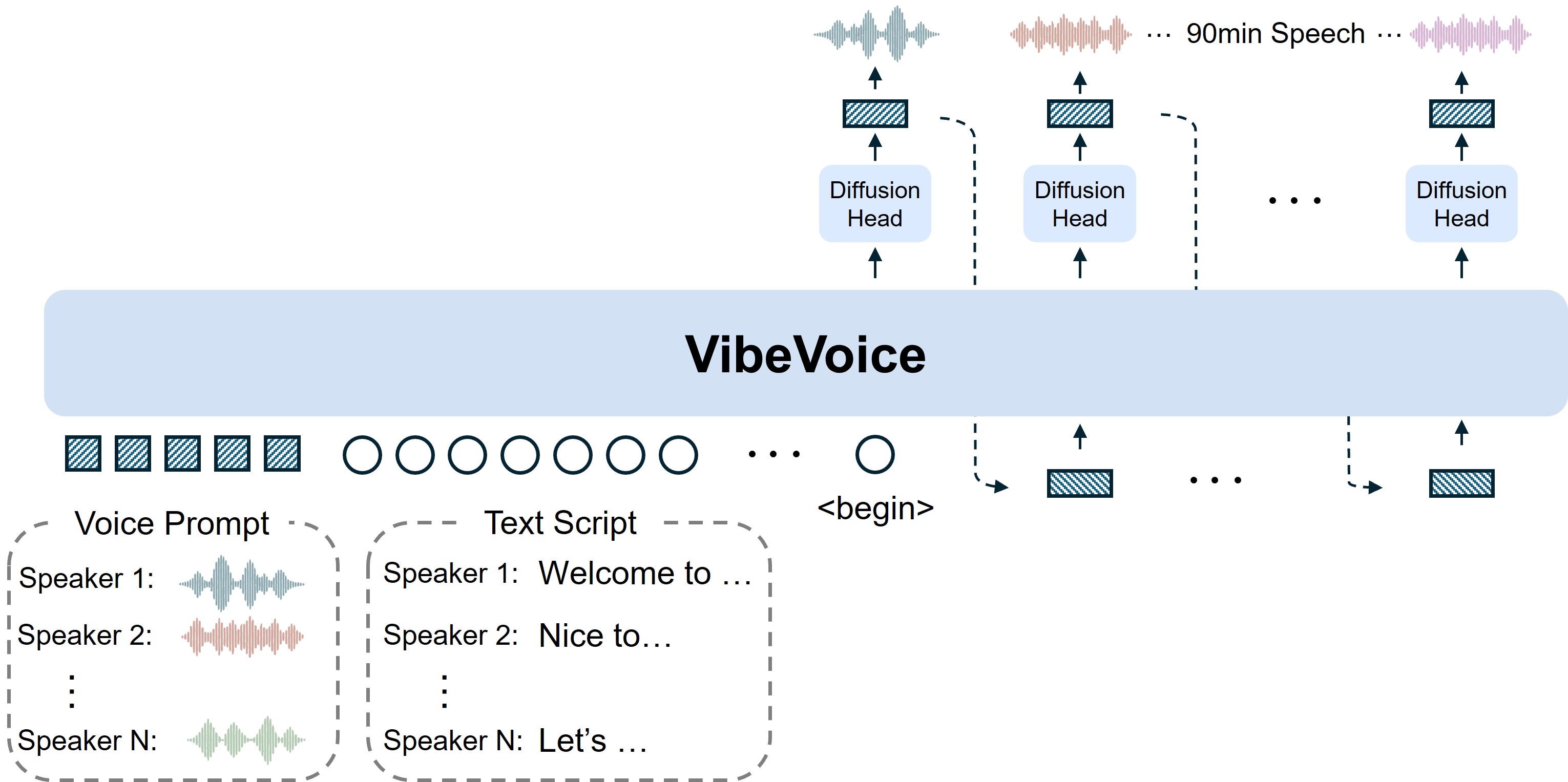
Он обрабатывает 60-минутный аудиофайл от начала до конца — за один проход.
Кто говорил. Когда говорил. Что именно сказал. Всё сразу. Не по частям.
Технология, которая делает это возможным, проста, но очень мощна: всего 7,5 токена в секунду. Сверхнизкая скорость обработки.
Благодаря этому 60 минут аудио укладываются в 64 000 токенов. Ничего не теряется. Никто из говорящих не забывается.
Кроме того:
→ Поддержка более 50 языков — не нужно вручную выбирать язык
→ Можно добавить собственный словарь — названия компаний, термины
→ Интеграция с библиотекой Hugging Face Transformers
→ ASR-модель на 7 млрд параметров — уже доступна на Hugging Face
Это open source. Вы можете взять код, доработать его и адаптировать под свои задачи.

На базе VibeVoice уже создан инструмент голосового ввода под названием “Vibing” — он работает на macOS и Windows.
А теперь посмотрите на это в контексте Азербайджана: сколько совещаний до сих пор расшифровываются вручную каждую неделю? Сколько рабочих часов уходит на редактирование каждого часа аудио?
Главный вопрос: какая азербайджанская компания сможет быстрее всех получить пользу от этой технологии? Юридическая сфера? Медицина?
⚠️ Примечание: VibeVoice — это исследовательский проект.
Он требует серьёзных GPU-ресурсов. Перед коммерческим использованием обязательно проведите тщательное тестирование.