
🚨 You probably haven’t heard of Microsoft’s AI that can recognize a 60-minute audio recording in a single pass.
Because most tools work like this:
Split the audio into small chunks → process each chunk separately → stitch the result back together.
At every split, context gets lost. It forgets who is speaking. The topic becomes fragmented.
VibeVoice thinks differently.
It processes a 60-minute audio file from beginning to end — in a single pass.
Who spoke. When they spoke. What they said. All at once. Not piece by piece.
The technology behind this is simple, yet powerful: only 7.5 tokens per second. Ultra-low-speed processing.
That allows 60 minutes of audio to stay within 64,000 tokens. Nothing is lost. No speaker is forgotten.
On top of that:
→ 50+ language support — no need to choose the language manually
→ You can add a custom word list — company names, technical terms
→ Integrated into the Hugging Face Transformers library
→ A 7B-parameter ASR model — already available on Hugging Face
It is open source. You can take the code, build on top of it, and customize it.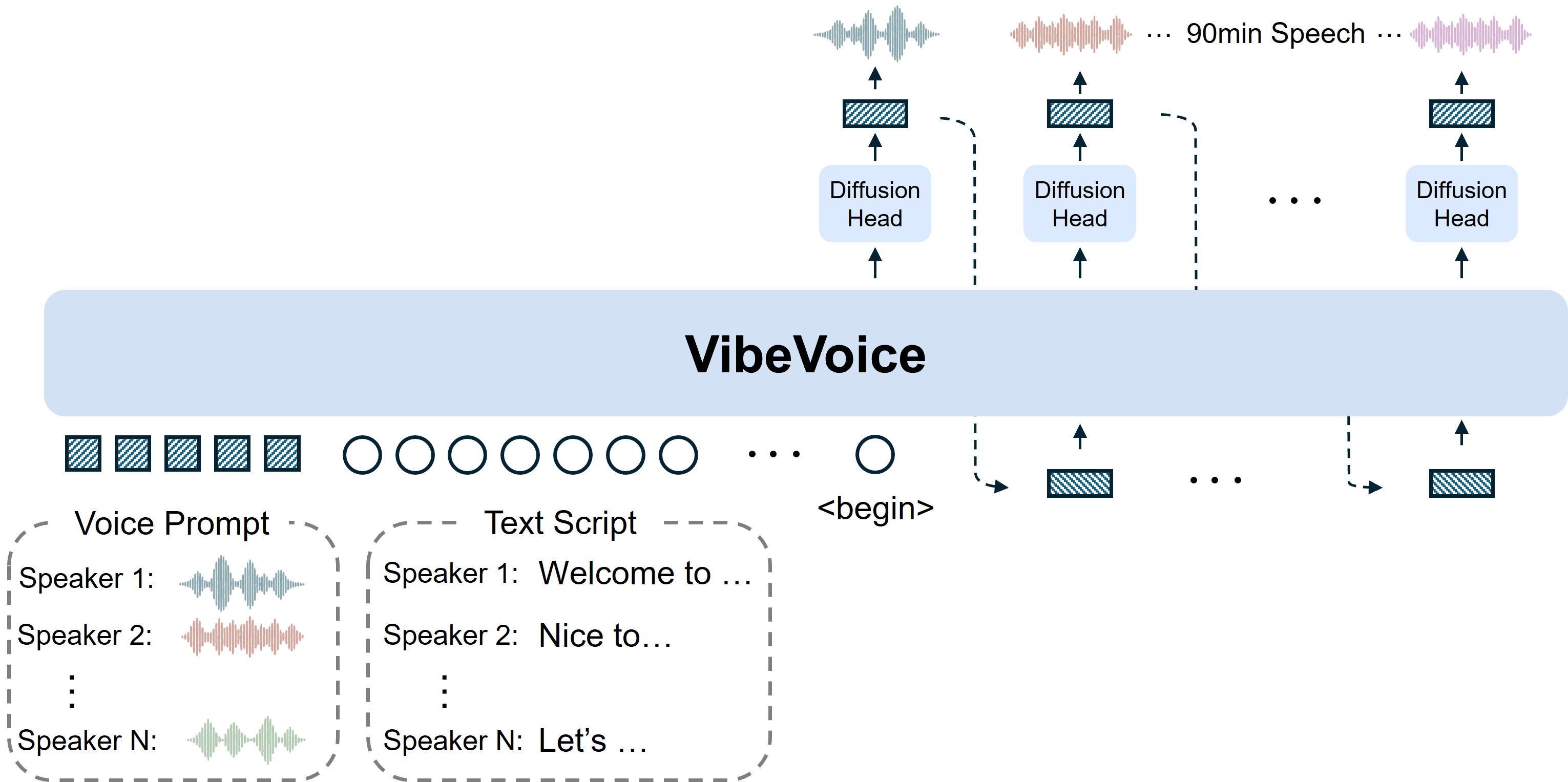
A voice-based input tool called “Vibing” has already been built on top of VibeVoice — and it works on macOS and Windows.
Now think about the Azerbaijani context: how many meetings are still transcribed manually every week? How many working hours are spent editing every hour of recorded audio?
The real question is: which Azerbaijani company could benefit from this technology first? Legal? Healthcare?
⚠️ Note: VibeVoice is a research-focused project.
It requires significant GPU resources. Test thoroughly before any commercial use.